


Identifying the Top Transformative and Emerging Data Annotation And Labelling Market Trends
The future of the AI data pipeline is being actively defined by several transformative Data Annotation And Labelling Market Trends that are pushing the industry towards greater efficiency, quality, and automation. As the demand for labeled data continues to outpace the supply of human annotators, the market is rapidly innovating to scale its operations and meet the increasingly complex needs of modern AI. These trends are not only shaping the next generation of annotation tools but are also redefining the role of humans in the AI training loop. The industry's forward-looking nature is a key reason for its positive growth outlook, with projections showing the market will grow from USD 3.10 billion in 2023 to USD 15.46 billion by 2034, driven by a powerful CAGR of 15.71%.
A dominant and accelerating trend is the rise of AI-assisted annotation. This represents a powerful shift from a purely manual process to a human-in-the-loop collaboration with AI. In this model, a machine learning algorithm performs a "pre-labeling" of the raw data—for example, by suggesting bounding boxes around objects it has already learned to recognize. A human annotator then simply needs to review, correct, and validate these suggestions, rather than drawing every label from scratch. This significantly speeds up the annotation process, reduces human effort, and can improve consistency. As the AI models used for pre-labeling become more accurate, this trend is dramatically increasing the productivity of human annotators and is becoming a standard feature in all leading annotation platforms.
Another powerful trend is the increasing use of synthetic data generation. Instead of relying solely on collecting and labeling real-world data, which can be expensive, time-consuming, and may not cover all possible edge cases, companies are now using computer graphics and simulations to generate perfectly labeled synthetic data. For example, an automotive company can create a photorealistic virtual world and generate millions of images of pedestrians in different lighting conditions and poses, all with perfect, pixel-level labels generated automatically. While synthetic data does not completely replace real-world data, it is a powerful complement that can be used to augment datasets and improve model robustness. This trend is creating a new and rapidly growing sub-segment of the market focused on data generation rather than just labeling.
Finally, a crucial emerging trend is the tight integration of data annotation into the broader MLOps (Machine Learning Operations) pipeline. In the past, data labeling was often a separate, one-off project that happened before model development began. The modern trend is to view data as an integral and continuous part of the entire machine learning lifecycle. This means that annotation platforms are now being designed to integrate seamlessly with data storage systems, model training frameworks, and model evaluation tools. This allows for an iterative process where a model's weaknesses can be automatically identified in production, and the relevant data can be sent back to the annotation platform for re-labeling and model retraining. This trend towards an integrated, continuous data improvement loop is a sign of the market's maturation and its central role in enterprise-grade AI.
Explore Our Latest Trending Reports:
Spain Business Process Outsourcing (BPO) Services Market
Categories
Read More
The latest update for Valorant, version 3.05, has officially gone live, bringing a host of changes aimed at improving gameplay balance and introducing new content. Players can now explore the newly added map, Fracture, which is available in its dedicated playlist for the next two weeks to help players familiarize themselves before it joins competitive rotation. One of the major highlights of...
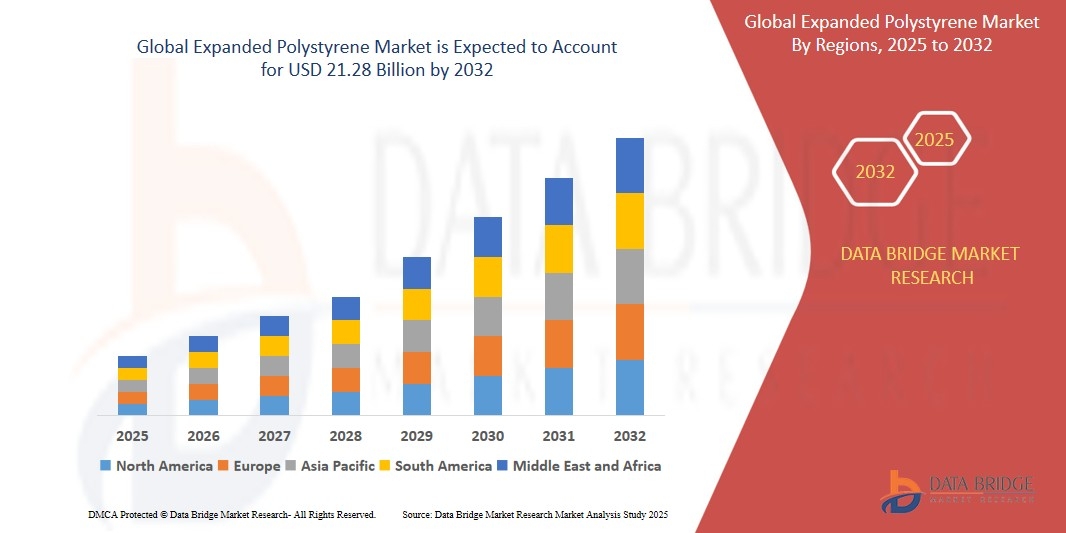
"Competitive Analysis of Executive Summary Expanded Polystyrene Market Size and Share CAGR Value The global Expanded Polystyrene market was valued at USD 11.21 billion in 2024 and is expected to reach USD 21.28 billion by 2032. During the forecast period of 2025 to 2032 the market is likely to grow at a CAGR of 8.4%, primarily driven by rising...
The Metal Sawing Machine Market Share is characterized by a competitive landscape with several key players dominating the market. Major manufacturers focus on product innovation, quality, and customer service to enhance their market presence. The distribution of market share is influenced by factors such as technological advancements, brand reputation, and the ability to provide customized...
Freight and logistics form the backbone of global trade and supply chain management, encompassing the planning, transportation, storage, and distribution of goods across local, regional, and international markets. The sector ensures that raw materials, finished products, and essential supplies are delivered efficiently, safely, and cost-effectively from manufacturers to consumers. With...

The food and drink sector responds in real time to changing consumer requirements and innovations in sourcing and production, as well as new methods of delivery. It comes to be defined by new cultural shifts, technological advances, global economics, and all food choices offered to users. The CAGR is 6.9%, with an estimated value of $531.2 Million , together with a transformative way foods are...
